
How I Stopped My Python Server from Crashing: The Memory Crisis Behind Vocalis
Feb 28, 2026
Local development lies to you.
On my Windows PC with 8GB RAM, Vocalis felt invincible.
Generate a 10-slide carousel?
Instant.
Convert to images?
Smooth.
Zip and upload?
Done.
Then I deployed to production.
512MB RAM.
Three users clicked “Generate Carousel.”
The server died.
Not slow.
Not degraded.
Killed.
OOM (Out of Memory).
This wasn’t an AI problem.
It was a rendering architecture problem.
And solving it forced me to understand memory at a level most SaaS tutorials never touch.
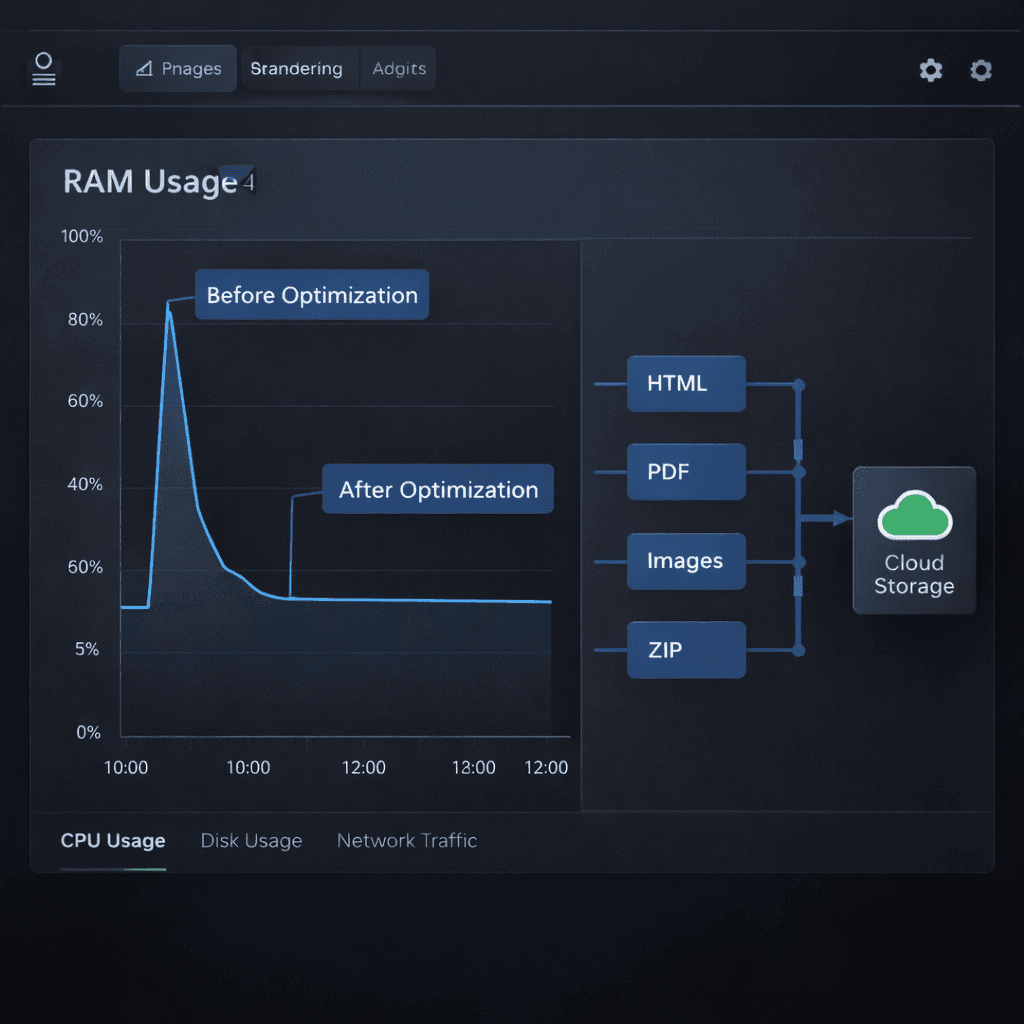
The Pipeline Anatomy
Here’s what happens inside Vocalis when you generate a carousel:
Raw idea
→ Jinja2 renders structured HTML
→ WeasyPrint converts HTML to PDF
→ pdf2image converts PDF pages to JPEG bitmaps
→ Images are zipped
→ Files uploaded to Supabase Storage
Each step allocates memory.
The problem wasn’t any single step.
It was concurrency.
I had used:
asyncio.gather()
PDF rendering and image conversion ran simultaneously.
This meant:
• PDF buffer alive in memory
• Jinja environment alive
• Bitmap arrays being allocated
• Python runtime overhead
All at once.
Peak memory skyrocketed.
The Math of Bitmaps
Most developers underestimate image memory.
A 1080×1080 JPEG might be 200KB on disk.
But in RAM?
It’s uncompressed.
Memory footprint calculation:
1080 × 1080 × 4 bytes (RGBA) ≈ 4.6MB
Ten slides?
≈ 46MB raw pixel data.
Add:
• PDF buffer
• Python objects
• Template environment
• Upload buffers
One request could easily exceed 100MB.
On a 512MB instance, three concurrent requests = termination.
The OS doesn’t negotiate.
It kills.
Fix 1: Sequential with Explicit Cleanup
Parallelism was the enemy.
We removed asyncio.gather().
Now the flow is disciplined:
Render PDF
Upload PDF
del pdf_bytesgc.collect()Convert images
Zip and upload
The peak memory never overlaps.
Garbage collection isn’t magic.
But forcing cleanup before the next heavy operation keeps memory within bounds.
The server breathes.
Fix 2: The N+1 Logo Problem
WeasyPrint fetches assets via HTTP.
If a user’s logo appears on 10 slides, that’s 10 requests.
Network latency.
Memory buffering.
Redundant fetches.
We solved this by:
• Fetching the logo once
• Encoding it to Base64
• Embedding directly in HTML as data:image
Zero external calls during render.
Fewer moving parts.
More deterministic behavior.
Fix 3: The 96 DPI Sweet Spot
Originally, I used 150 DPI.
It looked sharp.
It was wasteful.
Most social media consumption is mobile.
96 DPI is sufficient for feed clarity.
Dropping to 96 DPI:
• Reduced memory usage ~40%
• Reduced processing time
• No visible loss on LinkedIn/X
Optimization is not about max settings.
It’s about context-appropriate settings.
Fix 4: pdftocairo > pdftoppm
pdf2image defaults to pdftoppm.
Switching to pdftocairo:
• Faster JPEG encoding
• Better memory behavior
• Lower CPU spikes
Sometimes performance gains don’t come from code changes.
They come from tool selection.
The Scale vs Resource Paradox
Every SaaS founder faces this question:
Upgrade the server?
Or optimize the system?
Scaling hardware is easy.
Optimizing architecture is hard.
But optimization compounds.
Because it forces you to understand:
• How your code interacts with RAM
• How libraries allocate buffers
• How concurrency impacts heap size
• How operating systems enforce memory limits
These are not “AI problems.”
They are systems problems.
And systems thinking is what differentiates products that survive from those that crash under load.
The Result
Before:
• 15 seconds generation time
• RAM spikes
• Server crashes
After:
• 6 seconds generation time
• Stable memory plateau
• Zero OOM kills
Same 512MB instance.
Better architecture.
The Bigger Lesson
Most AI tools are wrappers.
Vocalis is a rendering engine.
Under the hood, it’s:
FastAPI
Jinja2
WeasyPrint
Poppler
Supabase Storage
The AI layer gets attention.
The memory layer earns trust.
If you’re building SaaS with visual pipelines, understand this:
Optimization is not premature.
It is survival.
Conclusion
Optimization isn’t about writing shorter code.
It’s about respecting hardware constraints.
By applying surgical architectural fixes:
• We reduced generation time by 60%
• Achieved 100% stability
• Eliminated OOM crashes
• Preserved low infrastructure cost
Vocalis is live.
Not just as a content multiplier.
But as a memory-efficient, infrastructure-aware system built for real-world constraints.
Build your content empire on a stable engine:
[vocalis.so/launch]
Related Post
Latest Post

Tech founders don’t struggle with ideas — they struggle with context switching. This deep dive expla...
Mar 2, 2026


Subscribe Us
Subscribe To My Latest Posts & Product Launches





